Apache Kafka Essentials

The Apache Kafka Essentials article provides an overview of what Kafka is, its key features, architecture, and why it is essential for modern applications.
- What is Publish/Subscribe Messaging?
- What is Apache Kafka?
- Use Cases for Apache Kafka
- Kafka Architecture Overview
- Kafka Topics
- References
In today’s digital world, data is being generated at an unprecedented rate. This data needs to be collected, processed, and analyzed in real time to make informed decisions. Apache Kafka, a popular open-source distributed streaming platform, plays a crucial role in handling real-time data streams. In this blog post, we will dive deep into what Apache Kafka is, its key features, architecture, and why it is essential for modern applications.
What is Publish/Subscribe Messaging?
Publish/Subscribe Messaging, often abbreviated as Pub/Sub, is a messaging communication pattern where senders (publishers) produce messages and send them to a central broker or mediator without specifying a specific recipient. Subscribers, on the other hand, express interest in certain types of messages and receive only those messages that match their interest. The central broker or mediator is responsible for managing the subscriptions and ensuring that messages are delivered to the appropriate subscribers.
What is Apache Kafka?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation. It’s designed to handle real-time data feeds with high throughput and low latency. Kafka operates as a distributed publish/subscribe messaging system, offering durable message storage and fault-tolerant capabilities. Commonly used for building real-time data pipelines and streaming applications, Kafka’s architecture allows it to scale easily and serve as a central hub for large volumes of data.
Use Cases for Apache Kafka
- Real-Time Analytics: Kafka can be used to collect and analyze data in real-time, enabling businesses to make informed decisions quickly.
- Log Aggregation: Kafka can be used to collect logs from various services and applications, aggregate them, and make them available for analysis and monitoring.
- Stream Processing: Kafka can be used to build applications that process data streams in real-time.
- Event Sourcing: Kafka can be used as an event store to implement event sourcing architectures.
- Data Lakes: Kafka can be used to ingest data into data lakes or data warehouses for further analysis.
Kafka Architecture Overview
The architecture of Kafka is designed to ensure scalability, durability, and fault tolerance.
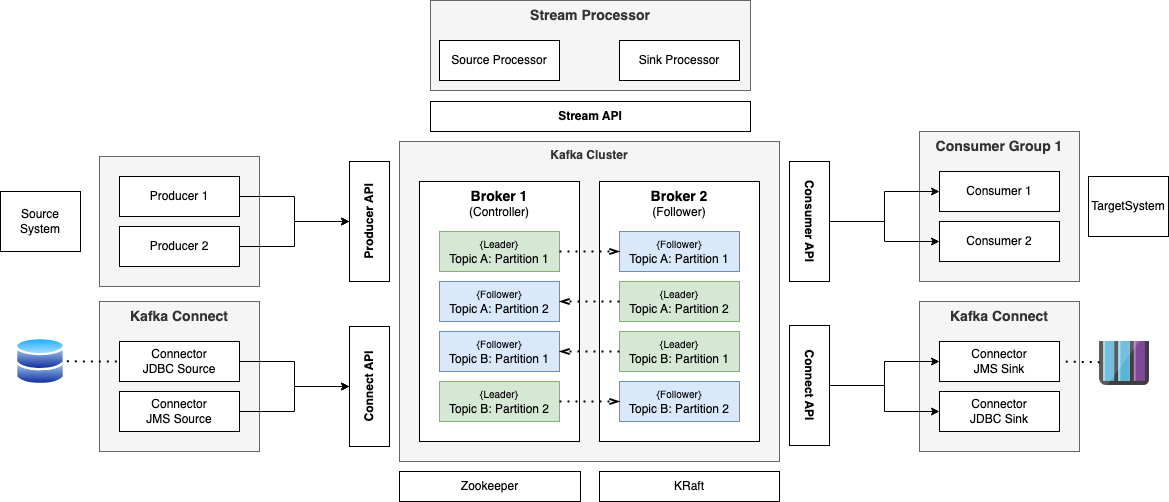
Kafka Architecture Overview
It consists of the following key components:
- Producer: The producer is responsible for publishing data to Kafka topics. Producers send data to Kafka brokers, and each piece of data is referred to as a message.
- Consumer: The consumer reads data from Kafka topics. Consumers subscribe to one or more topics and consume messages published by producers.
- Broker: A Kafka broker is a server that stores data and serves clients (producers and consumers). A Kafka cluster is made up of multiple brokers.
- Topic: A topic is a category or feed to which messages are published. Topics allow messages to be organized and provide a way for consumers to subscribe to specific categories of messages.
- Partition: Topics are divided into partitions, which are the basic unit of parallelism in Kafka. Each partition can be hosted on a different server, allowing Kafka to horizontally scale as more brokers are added to the cluster.
- Zookeeper: Zookeeper is a distributed coordination service that Kafka uses to manage its cluster nodes. It helps in keeping track of the status of Kafka brokers, partitions, and replicas.
Kafka includes five core apis:
- The Producer API allows applications to send streams of data to topics in the Kafka cluster.
- The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
- The Streams API allows transforming streams of data from input topics to output topics.
- The Connect API allows implementing connectors that continually pull from some source system or application into Kafka or push from Kafka into some sink system or application.
- The Admin API allows managing and inspecting topics, brokers, and other Kafka objects.
Kafka Topics
- Messages in Kafka are categorised into topics, in other words, messages are organized and durably stored in topics.
- Topics are broken down into a number of partitions.
- Messages within a topic can’t be queried, instead Producers write to a topic and consumers read from a topic.
- Messages within a topic are not deleted after consumption and can be read as often as needed (unlike traditional messaging systems).
- Topics in Kafka are always multi-producer and multi-subscriber:
- a topic can have zero, one, or many producers that write messages to it.
- a topic can have zero, one, or many consumers that subscribe to these messages.
- Topic Configuration define how long message is kept.
- A topic is identified by its name and can support any message format (e.g., Json, Avro, text file, binary).
- A sequence of messages (events) is called a data stream.
- A data stream in Kafka is considered to be a single topic of data. (no matter the number of partitions).